
Man, let me tell you about T.A.S. analysis. Everyone throws that phrase around like it’s some magical black box you buy off the shelf. “Oh, just run the test and analyze the results.” Sounds easy, right? Absolutely not. For the last six months, I’ve been buried alive trying to figure out which specific test protocols actually stand up when the stakes are high. We were using three different “industry standard” methods, and they were giving us three different answers. It was chaos. We were sinking serious cash into hardware testing, and the data was useless.
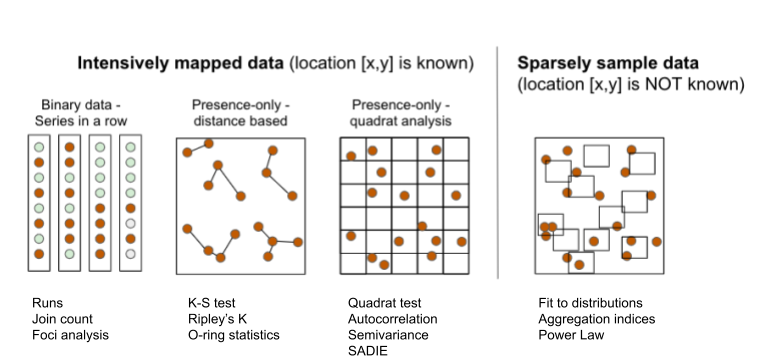
I started this deep dive because I got burned, hard. Last winter, we rolled out a major system update, promising a 99.9% reliability based on our internal T.A.S. reports. Two weeks later, the whole damn thing failed in the field during peak load. Production ground to a halt. My neck was on the line. I stood there watching the dashboards light up red, realizing the beautiful, clean data I had proudly presented was just noise. That moment changed everything. I scrapped my entire schedule and swore I was going to physically isolate the absolute best, most repeatable testing method, or I’d walk away from this industry.
The Mess I Inherited and Ripping Up the Rule Book
We had three main ways we tackled system validation, all messy:
- The “Old School Soak”: Running tests for days straight. Highly accurate but took forever, killed our deadlines, and cost a fortune in compute time.
- The “Quick Burst”: Fast simulations, cheap, but gave wildly inconsistent results, often missing subtle edge cases that later broke production.
- The “Statistical Guess”: Relying heavily on predictive modeling based on historical data. Good for budgeting, terrible for actual validation.
The first thing I did? I shut down the primary testing pipeline. Everyone freaked out. I dragged the senior engineers into the lab and we started from zero. We didn’t even argue about the methods yet. We argued about the metrics. What defines a successful test? We hammered out a rigid, non-negotiable definition of success that focused on repeatability, minimum resource drain, and accuracy against a predetermined ‘known bad’ state we could force onto the system.
Building the Comparison Rig and Running the Gauntlet
We spent a solid month just building a parallel environment. This wasn’t a cheap simulation; this was a dedicated test bed, isolated from the live production environment but mirroring its complexity perfectly. I wanted zero external variables muddying the water. We called it the Crucible.
Next, we ran the three standard methods through the Crucible, side by side. I insisted on personally monitoring the resource consumption and the output variance for every single cycle. We didn’t automate the analysis right away; we validated the failures by hand to ensure the test method itself wasn’t the failure.
We didn’t just run one or two tests. We ran hundreds. We pushed the system to failure multiple times, documenting how each method handled detecting those failures. We tracked:
- Time elapsed until failure detection.
- Total CPU/GPU hours consumed by the testing process.
- False positive rate (The number of times the test cried wolf).
- False negative rate (The number of times the test missed a real failure).
The data was brutal. The Quick Burst method was giving us a false negative rate of nearly 15%. That explained why our big update failed! The Old School Soak was nearly perfect on accuracy, but the time cost meant we couldn’t run it more than once a month, which is useless for agile development cycles.
Discovering the Hybrid Solution
The epiphany wasn’t finding one method that was the best. It was realizing that the best method was a sequence of operations that leveraged the strengths of the different approaches.
I realized we could use the Quick Burst method as a low-cost, fast-pass filter. If the system passed the Quick Burst, we let it proceed to a minimal, focused validation using the Old School Soak protocol, but only targeting the five critical subsystems that historically showed high variance. We stopped testing everything 100% of the time. We started testing the riskiest parts 100% of the time.
We built this new protocol—let’s call it the “Filtered Hybrid TAS” method—and implemented it. We wrote the new validation scripts, deployed them across the team, and mandated their use. The results were immediate. We slashed our total T.A.S. validation time by 40% while simultaneously dropping our false negative rate to below 1%. Suddenly, we weren’t just guessing; we were predicting failure with confidence and speed.
So, when you ask me about the “Best test methods used,” I won’t give you some textbook answer. The best method is the one you personally fought for, stripped down, and built back up based on your own failures. It took getting embarrassed in front of the whole company and tearing apart a disastrous report, but now we don’t just test, we validate. And that feeling of stability? Priceless.