
Man, trying to follow the Spanish league in real time used to drive me nuts. I mean, everybody wants those table updates instantly, right? Especially when it’s crunch time, like Atlético Madrid playing Betis. You click refresh, and it’s always lagging. The official sites? Forget about it. They clog up worse than my old bathtub drain. I swear, they must run those league table updates on a server powered by a hamster wheel.
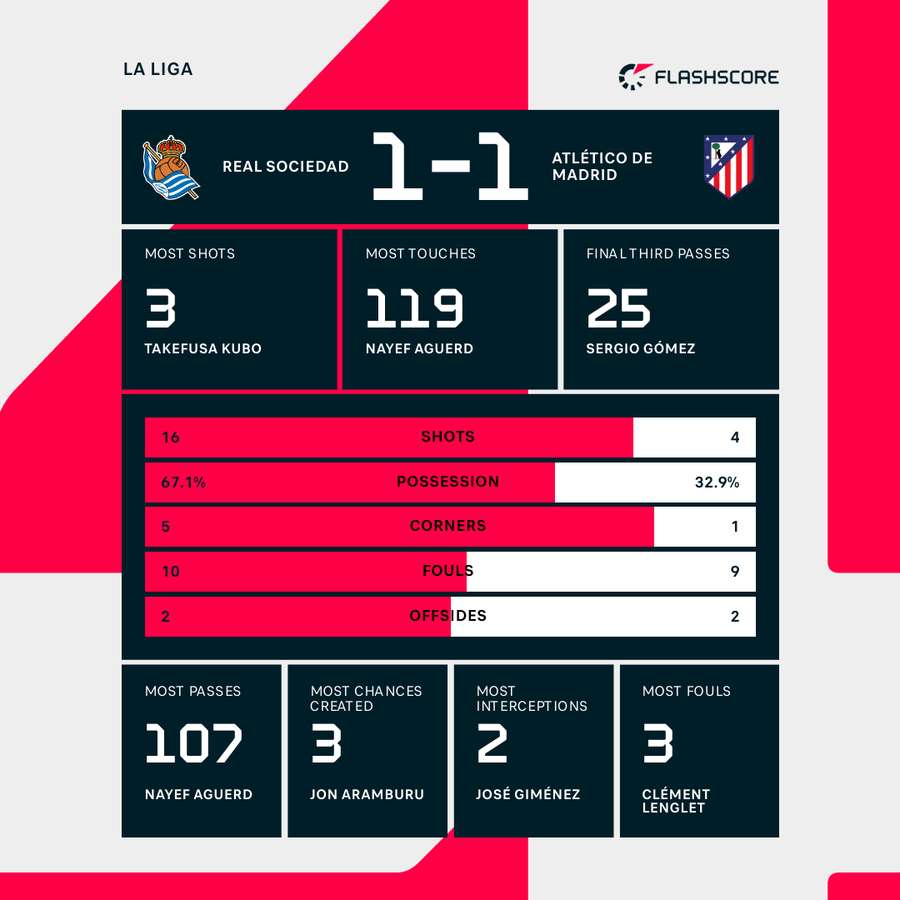
I got sick of it. Absolutely fed up waiting five minutes after a goal to see if the table positioning had actually shifted. So I decided, fine, I’m building my own system just to get the damn numbers fast. This wasn’t about professionalism; this was purely a selfish endeavor fueled by annoyance.
The Initial Disaster: Trying to Be Smart
The first thing I did was try to stack up three different public APIs. I thought, ‘If one fails, the other two pick it up.’ Total nonsense. I wired up a simple Python script, slapped on Flask because everyone said Flask was the quick way to set up a web endpoint. It was a disaster, a true mess of cobbled-together pieces.
- First struggle: Rate Limits. The most promising API kept throwing rate limits at me, even though I was paying them a few bucks a month. I spent two solid days trying to figure out proxy rotation just to fetch five numbers reliably. It felt like I was fighting a DDoS war against myself.
- Second struggle: Formatting hell. The second data source I tried was free, which should have been my first warning sign. It came in some weird, convoluted JSON format that required a huge parsing library just to identify the team name. My little server started sucking RAM like a vacuum cleaner. It was sluggish and constantly needed restarting.
- Third struggle: Staleness. The third API was stable and reliable, I’ll give it that. The problem? It only updated every 15 minutes. Who needs 15-minute-old data in a live soccer match? If a team scores three quick goals, my “instant update” system would be half an hour behind. Pointless.
I realized I had created a technical monstrosity. It was like the example I always hear about those big tech companies—they use five different languages to solve one basic problem, and none of them talk to each other properly. That was me, except I was doing it with three different API schemas and one struggling Flask application.
The Pivot: Embracing the Ugly Solution
I scrapped the whole three-API spaghetti mess. I deleted the Flask setup. That’s when I realized I was trying to run a marathon when all I needed was a quick jog around the block. I boiled it down. I picked one source—just one official league table site—that I knew updated fast, even if their site design looked like it was coded in 2005. They are ugly, but they are quick, and that’s what mattered.
I switched gears entirely and went old school. I decided I was going to scrape it. Yeah, scraping, I know, the dirty word. But for getting raw, instant, volatile data like positions in a fast-moving league, sometimes the direct approach is the only way.
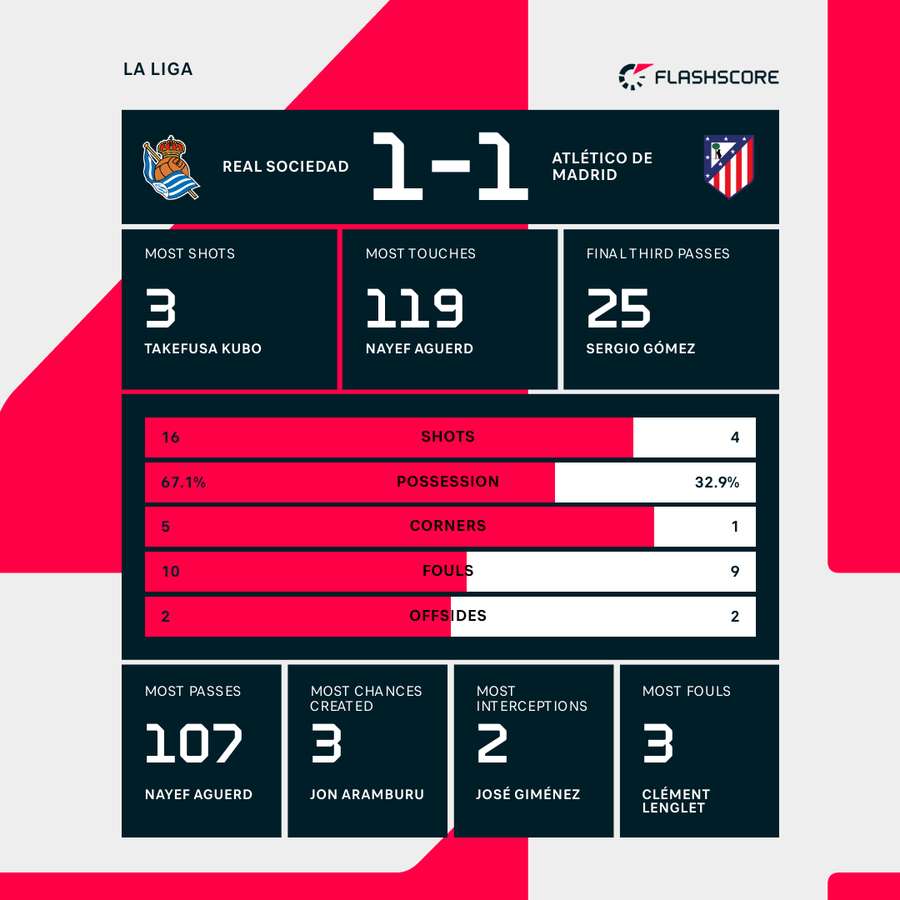
I wrote a new, short, simple script. This time, I used good old requests and BeautifulSoup. I specifically targeted the table ID elements and the row data related to the team positions (the “posiciones” data). I didn’t care about the colors, the team logos, or the fancy graphics. I just wanted the raw number telling me where Atlético was sitting and where Betis was sitting, especially during the 90 minutes they were actually playing.
Then I set up a ridiculously aggressive cron job. Most people running scripts like this usually set them for every minute. Not me. I needed it instant. I configured the cron job to run every 30 seconds. Yes, I know, I’m probably stressing that server a bit, but hey, it’s public data, and I’m hitting a specific endpoint, not the whole homepage. It runs, grabs the specific numbers, parses them into a tiny text file, and then my simple internal endpoint just reads that text file. No database needed. Zero latency from the file read.
The Reality of Maintenance
Now, does this setup break sometimes? Absolutely. Every time that source website decides to rename a class from team-position-data-1 to team-position-data-v2, my script explodes. I spend about an hour every month fixing some stupid typo or structural change they made in their HTML, but honestly, it’s still faster than waiting for the ‘official’ data pipes to unclog themselves or troubleshooting some bloated commercial API.
The takeaway? Stop trying to be fancy. If you need immediate results on something simple and highly volatile, like league standings that change mid-game, you have to go straight to the source. That initial mess of APIs taught me that complication just adds latency and failure points. Now, I bypass the middlemen, point my tiny script directly at the data, and hit refresh until it bleeds the answer out. It’s ugly, it’s functional, and most importantly, I finally get those league table updates before the commentators even finish yelling.