
The Grind: Why I Bothered With a Fake World Cup
Man, predictions for the World Cup are everywhere, right? Every sports pundit, every drunk guy in the pub, and definitely every single betting site has a firm opinion. I used to just roll my eyes and trust my gut, which, I gotta tell you, got me burned more times than I care to admit. It was always the random upset, the unexpected red card, or the penalty shootout that derailed my whole weekend. I was tired of luck. I wanted numbers. I wanted brute force.

My last real breaking point happened during the Euros two years back. I had this mate, let’s call him Mark. Mark doesn’t watch football, maybe two games a year. But whenever we threw a casual tenner on a game, he’d always win. And I mean always. He’d pick the dull 0-0 draw or the random 88th-minute goal from some obscure team just by “feeling it.” I confronted him about it one day after he took my cash following a truly impossible result, and he just smirked and said, “Stick to spreadsheets, man, I’ll stick to vibes.” That comment, that absolute dismissal of effort versus his pure, undeserved luck, flipped a switch in my head.
I wasn’t going to rely on vibes anymore. I was going to beat his vibes with a mountain of pure, cold simulation. That’s the real reason I kicked off this whole simulated World Cup project. It wasn’t about proving anything to the world; it was about proving Mark wrong, even if he never saw the data.
Building the Beast: The Dirty Setup
First thing I did was gather some rough power rankings. I didn’t mess around with fancy proprietary algorithms. I just scoured a bunch of sports sites for their Elo ratings or similar “strength indices” and shoved them into a massive spreadsheet. I simplified everything. Each team got a single ‘Power Score,’ a number between 1500 and 2100. Super easy, super rough.
Next came the core logic, which was the fun part. I had to figure out how two teams, say Brazil (1900) and Iran (1650), actually played a match in my code. It basically came down to this:
- Take the difference between their Power Scores. This gives the baseline chance of winning.
- Add a massive, totally random element. I literally generated a random number (a ‘Luck Factor’) for both teams for that one match. You know, to account for bad calls or unexpected injuries.
- The team with the higher final combined score (Power + Luck) wins the simulated match.
I built this engine, not in some fancy environment, but just in a local Python script I hacked together over a weekend. It looked messy, but it worked. It could read the scores and spit out a winner, a loser, or a draw.
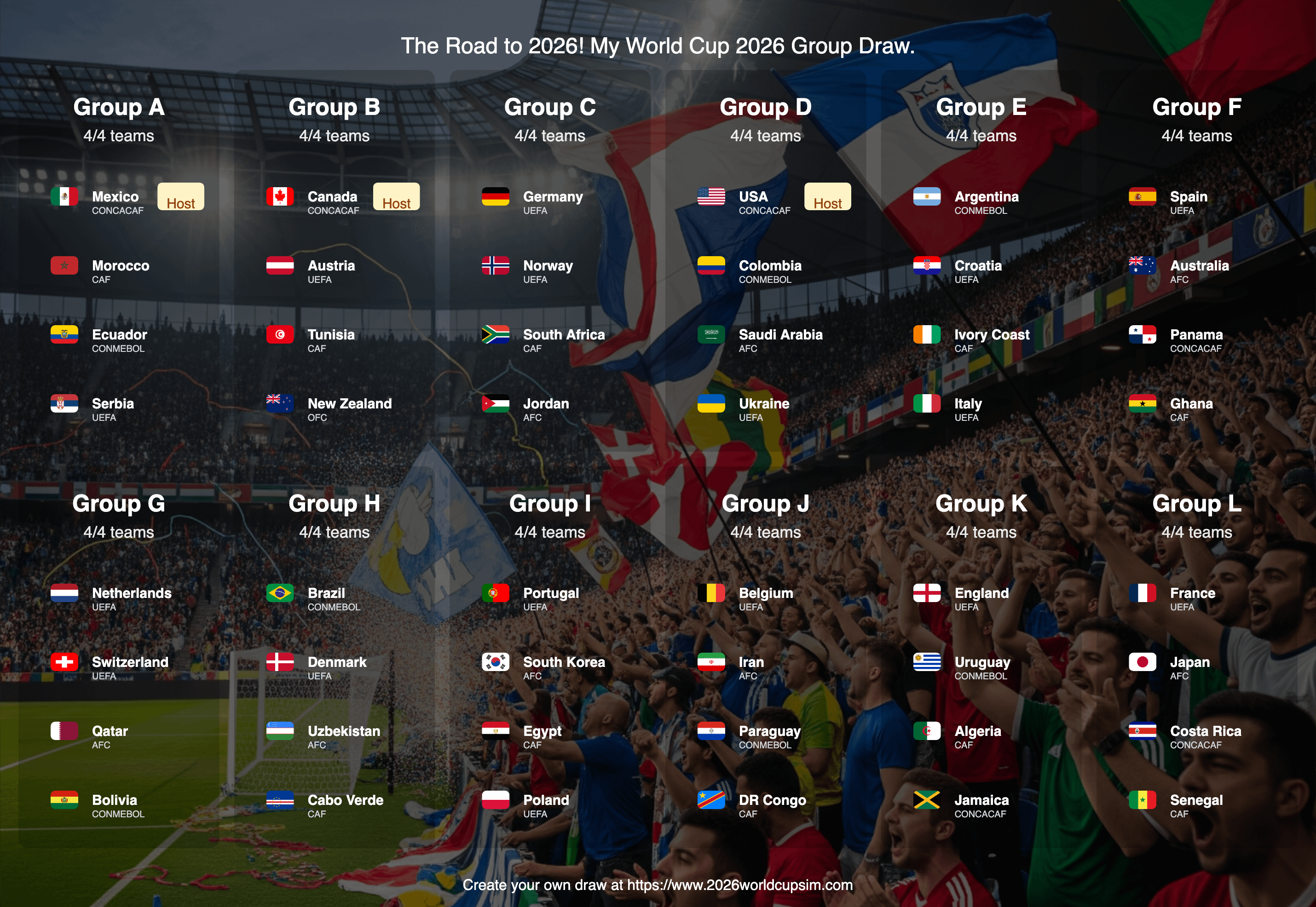
The Long Haul: 10,000 Tournaments
The real commitment started when I actually ran the thing. I didn’t want to run the World Cup once. Anyone can do that. I needed volume. I wanted the probabilities. So, I instructed the script to run the entire 32-team tournament—group stage, knockout rounds, quarters, semis, the final—all 64 matches, ten thousand times. That’s a lot of simulated football.
I kicked it off and just let it grind. My old laptop fan sounded like a jet engine trying to keep up. I’d check back every hour, watching the winner count slowly tick up for each potential champion. It was hypnotizing. I just kept track of two things:
- How many times did a team win the final?
- How many times did a team make the final four?
The numbers started to stabilize after about 5,000 runs. You could see the heavy favorites consistently taking home the cup, but every now and then, a massive underdog, powered entirely by a string of high ‘Luck Factor’ rolls, would sneak into the semi-finals. It felt chaotic, but also surprisingly realistic. The numbers showed that even a team with a 5% chance of winning will still win 500 times out of 10,000 runs, which is exactly why upsets happen in the real world.
The Verdict: How Real is This?
When the dust settled, I had a massive Excel sheet showing the cold, hard probability of every team winning the whole thing. The favorites were still the favorites—Brazil, France, etc.—but the simulation forced a sense of reality onto their chances. Instead of someone confidently saying “Brazil will win,” my data said, “Brazil has a 19.4% chance of winning.” Big difference, right?
I looked at the results and had to laugh. The simulation predicted that a team that gets knocked out in the real world’s quarter-finals had won my fake tournament over 1,500 times. That’s when the realization hit me: The simulation is only as real as the inputs, but the randomness is what makes it honest. My simple Power Score combined with that giant random dice roll proved that a massive amount of the World Cup is pure, beautiful chaos.

I never showed Mark the full data. I just quietly started making my own small bets based only on the probability percentages my script spat out, ignoring the headlines and the vibes. Did I suddenly become rich? Nope. Did I start beating Mark? Not every time, but enough that he stopped feeling so smug about his “vibes.” The real take away is this: building the simulation didn’t give me the right answer. It just showed me that the right answer is a moving target, and that even the best team has a bad day one out of five tries. I spent hours building a machine just to confirm that life, and football, will always find a way to surprise you. But at least now, I know how surprised I should be.