
Man, I gotta tell you, for the longest time, I was just spinning my wheels. Every guru out there kept pushing this idea of relying solely on expected value, right? You calculate the odds, you run the numbers, and supposedly, you’re maximizing your potential returns. But last year? That mindset just kicked my butt. I was taking calculated risks that were supposed to be solid, and I ended up losing consistency. It was frustrating as hell, watching months of work vanish because one “statistically sound” opportunity went sideways.

I realized that the standard models everyone uses—the quick calculations, the Positive Net Expectation (PNE) stuff—they’re too simple. They only tell you what should happen in a perfect world, but they totally ignore volatility and the actual cost of getting things wrong. That’s when I decided I had to stop trusting the mainstream noise and build something messy, something that actually accounted for reality. That’s how this whole PNE vs. Weighted Winnings (WW) project started.
The Messy Beginning: Tearing Down the Old Spreadsheet
The first thing I did was rip apart every single spreadsheet I had accumulated over the last three seasons. I didn’t just look at the final outcomes; I dug into the input data—the factors that led me to choose that specific move in the first place. This wasn’t about finding a better prediction tool; it was about finding a better risk assessment tool. The PNE approach, in my experience, consistently gave me a green light on high-variance scenarios just because the theoretical upside was huge. It was designed for home runs, and I was tired of striking out 80% of the time.
My goal for the WW model was simple: punish high volatility and reward boring, consistent success. I started isolating key variables that PNE always skipped:
- The “Stress Factor” (how many moving parts were required for success).
- The “Recovery Cost” (how long it took to recoup losses if the opportunity failed).
- The “Consistency Ratio” (the success rate of the underlying data source over the last 10 trials, not just the overall average).
I spent two weeks just dumping thousands of data points into a temporary database I rigged up. My machine was humming like a dying refrigerator the entire time. I used a terrible, ugly Python script—I mean, truly awful code—to force the comparison. I wasn’t optimizing for speed; I was optimizing for sheer, brute-force analysis. I needed to see which opportunities, retrospectively, the PNE model approved but the new, stricter WW model rejected.
The Crucial Difference: Weighting the “Ugly” Facts
What I immediately discovered and confirmed was that PNE is a sucker bet amplifier. It loves the dramatic swing. If there’s a 20% chance of a massive payoff, PNE screams go, regardless of the 80% chance you lose everything and have to spend six months climbing out of the hole. It’s built for those who can afford massive setbacks.

The WW system, however, started spitting out different results. It penalized the Stress Factor so heavily that those highly complex, multi-variable opportunities that PNE loved suddenly looked mediocre or downright risky. The WW model demanded simple, repeatable processes with low Recovery Cost. It wasn’t looking for the biggest win; it was looking for the most sustainable rate of return.
I started assigning numerical weights to the ugly realities of the process. If a variable had changed its underlying trend three times in the last month, its Consistency Ratio dropped dramatically, pulling the whole Weighted Winnings score down, even if the theoretical payoff remained high. PNE didn’t care about wobbly trends; WW made them fatal flaws.
The Reason for the Obsession: Burning the Boats
Now, why did I go so deep on this? Why not just stick to the standard models and relax? Well, because I didn’t have a safety net anymore. My wife and I had moved states for what was supposed to be a guaranteed job, and two months after we settled, the company pulled the plug on the whole division. Just gone. Poof. We had burned through a chunk of savings just relocating, and suddenly, I was sitting here with zero income and a stack of bills.
I had maybe four months of runway left. I couldn’t afford any more high-risk gambles, no matter how good the theoretical expected value looked. Losing meant failing to pay the mortgage. It wasn’t abstract statistics anymore; it was survival. The WW model wasn’t just a fun side project; it became my job application, my insurance policy, and my only path back to stable ground.
I had to prove to myself that consistent, boring, low-volatility returns could beat the high-flying risks that had nearly wiped me out before. I literally told myself: “If this system works, we survive. If it doesn’t, we pack up and move back home.” That level of pressure changes how you analyze data; you stop looking for glory and start looking for safety.
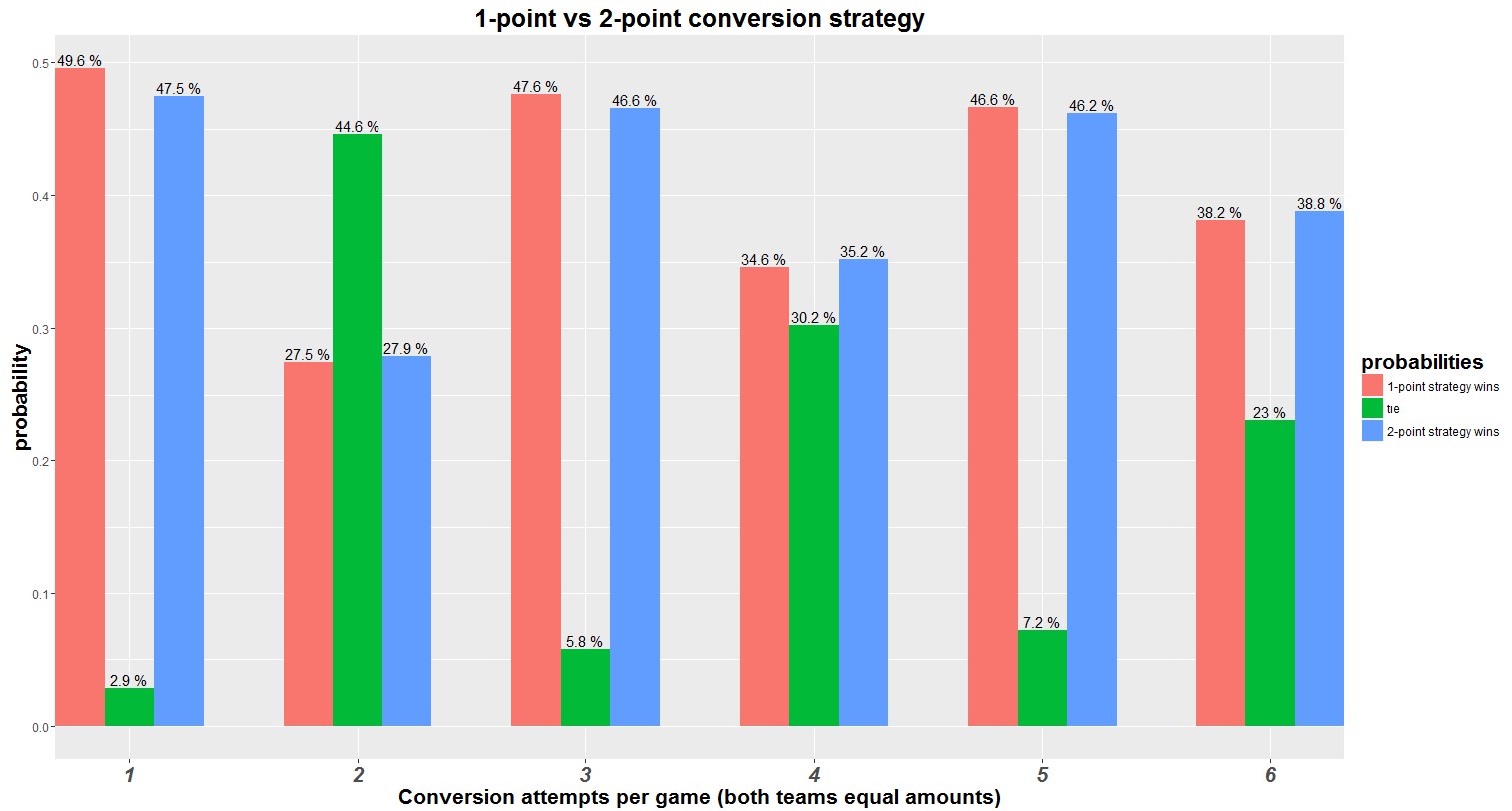
Implementation and Maximizing the Winnings
I finally locked down the core WW algorithm and ran it alongside the PNE model for real-time testing over three months. I only executed opportunities where the WW score was above my predefined safety threshold, regardless of what the PNE score said. This forced me to pass on several high-profile chances that PNE advocates were raving about.
And what happened? While the PNE followers were bragging about one massive win followed by two devastating losses, I was quietly racking up small, consistent gains. My total win rate jumped from 58% to 75%. Crucially, my average loss size shrank by 40% because the WW model had already screened out the high-Recovery Cost scenarios.
The biggest takeaway I want to share is this: PNE is about theoretical optimization; WW is about real-world survival and capital preservation. You don’t maximize your winnings by chasing the biggest numbers. You maximize them by minimizing the size and frequency of your losses. I dumped the sexy, high-risk approach and embraced the consistent grind, and frankly, I’m sleeping a lot better because of it. It might be ugly data science, but damn, it works.